Google shows off new smaller generative AI tools and an AI agent on your phone
Google wants to seize momentum from rivals like OpenAI in the generative AI race - and its latest LLM updates could turn the tide

Google has showcased a number of updates to its generative AI tools and a few peeks at future products, as it continues its efforts to seize momentum from OpenAI.
Earlier this week OpenAI unveiled its latest flagship LLM , GPT-4o, which is able to joke and flirt with users; following that it has been Google’s chance to detail where it has got to with its generative AI products at its Google I/O event.
Late last year Google unveiled its first multimodal LLM Gemini 1.0 in three sizes: Ultra, Pro and Nano for on-device processing. It follows this with Gemini 1.5 with improved performance and a context window of one million tokens (one token is four characters or somewhere around three-quarters of a word so 100 tokens is 75 words).
Because, the company said, developers want an LLM with lower latency and lower cost; it has now added Gemini 1.5 Flash to the portfolio.
Gemini 1.5 Flash is the fastest Gemini model served in the API and it is optimized for high-volume, high-frequency tasks which Google said makes it more cost-efficient to serve.
Although it’s a lighter weight model than 1.5 Pro, it’s still capable of multimodal reasoning across vast amounts of information, according to Google DeepMind CEO Demis Hassabis.
He said 1.5 Flash is suited to summarization, chat applications, image and video captioning, or data extraction from long documents and tables. It has been trained by 1.5 Pro through a process called “distillation,” whereby the most essential knowledge and skills from a larger model are transferred to a smaller model.
The model has a one-million-token context window by default, which means you can process one hour of video, 11 hours of audio, codebases with more than 30,000 lines of code, or over 700,000 words.
Both 1.5 Pro and 1.5 Flash are available in public preview with a 1 million token context window in Google AI Studio and Vertex AI.
Google Gemini 1.5 Pro updates
Google also introduced updates to Gemini 1.5 Pro which it styles as its best model for general performance across generative AI tasks. These include upping the model to a two million token context window.
The company said this would give the model “near-perfect recall on long-context retrieval tasks” making it possible to accurately process large-scale documents, thousands of lines of code or hours of audio and video.
To illustrate this Google had the model analyst a 402-page transcript of the Apollo 11 Moon landing – accounting for 320,00 tokens, and then hunted through for ‘comedic’ moments, which it did.
Hassabis said Google had also enhanced its code generation, logical reasoning and planning, multi-turn conversation, and audio and image understanding. “We see strong improvements on public and internal benchmarks for each of these tasks,” he said.
This means that Gemini 1.5 Pro can now follow increasingly complex and nuanced instructions, he said. “We’ve improved control over the model’s responses for specific use cases, like crafting the persona and response style of a chat agent or automating workflows through multiple function calls.”
He said 1.5 Pro can now reason across image and audio for videos uploaded in Google AI Studio, and that 1.5 Pro is being integrated into Google products, including Gemini Advanced and in Workspace apps.
Gemini on Android
Google said Gemini on Android will use generative AI to get better at understanding the context of what’s on your screen and what app you’re using.
Android users will soon be able to bring up Gemini's overlay on top of the app they are using. Google gave the example of dragging and dropping generated images into Gmail or Google Messages, or tapping “Ask this video” to find specific information in a YouTube video.
With Gemini Advanced users will have the option to “Ask this PDF” to quickly get answers from documents. Google said this update will roll out to “hundreds of millions of devices” over the next few months.
It said that, starting with Pixel later this year, it will be introducing Gemini Nano with Multimodality to allow phones to not just process text input but also understand more information in context like sights, sounds and spoken language.
Google said it is also testing a new feature that uses Gemini Nano to provide real-time alerts during a call if it detects conversation patterns associated with scams. Users would receive an alert if someone posing as a “bank representative” asks you to urgently transfer funds, make a payment with a gift card or requests personal information like card PINs or passwords, which are not the sort of thing the bank usually asks you to do.
“This protection all happens on-device, so your conversation stays private to you,” Google said, which this would be offered as an opt-in feature.
Project Astra
Google also showed off Project Astra, which Hassabis described as an ‘advanced seeing and talking responsive agent’.
Google illustrated this with a pair of videos featuring someone walking around Google’s London office and using the agent on a smartphone to identify objects and read software code. They then switched to smart glasses and the same agent was able to help fix a coding problem and come up with a name for the band (the band apparently featured a soft toy and a dog, which didn’t seem to bother the AI).
Hassabis said that in order to be truly useful, an agent needs to understand and respond to the complex and dynamic world just like people do, and to be able to take in and remember what it sees and hears in context so it can take action.
But said that getting response time down to something conversational is a difficult engineering challenge.
RELATED WHITEPAPER

“Over the past few years, we've been working to improve how our models perceive, reason and converse to make the pace and quality of interaction feel more natural.”
He said that, by building on Gemini, Google has developed prototype agents that can process information faster by continuously encoding video frames, combining the video and speech input into a timeline of events, and caching this information for efficient recall. These agents can better understand the context and respond quickly in conversation.
“With technology like this, it’s easy to envision a future where people could have an expert AI assistant by their side, through a phone or glasses,” he said.
None of these updates particularly grab the attention like OpenAI’s latest chatty release, apart from Project Astra which is still in development. However, showing off a multimodal assistant running on a smartphone will certainly put the pressure on Apple to come up with something similar, soon.

-
 Curing the cloud hangover: why organizations are rethinking public cloud
Curing the cloud hangover: why organizations are rethinking public cloudDiscover why IT leaders are stepping away from a "one-size-fits-all" public cloud approach, embracing cost predictability, and using private cloud to secure enterprise AI data
-
 Amazon targets agent safety gains with investment in team behind Lean programming language
Amazon targets agent safety gains with investment in team behind Lean programming languageNews The tech giant hopes support for the open source programming language could drive AI agent safety improvements


-
 ‘Chat is dead’: OpenAI plots ChatGPT ‘super app’ overhaul ahead of public listing – with agents and coding tools the new focus
‘Chat is dead’: OpenAI plots ChatGPT ‘super app’ overhaul ahead of public listing – with agents and coding tools the new focusNews The company looks set to spruce up ChatGPT with a particular focus on agents to drive subscriptions
-
 ‘The jobs picture is likely to be very different than we thought’: Sam Altman pours cold water on AI 'jobs apocalypse' claims – but that doesn’t mean there won’t be some workforce disruption
‘The jobs picture is likely to be very different than we thought’: Sam Altman pours cold water on AI 'jobs apocalypse' claims – but that doesn’t mean there won’t be some workforce disruptionNews OpenAI CEO Sam Altman “thought there would have been more impact” on white collar and entry-level jobs at this point
-
 Microsoft joins competitors in handing over AI models for advanced testing
Microsoft joins competitors in handing over AI models for advanced testingNews US and UK government agencies will evaluate the firm's frontier models, along with those from Google and xAI
-
 Google is building its own OpenClaw alternative — Remy ‘elevates the Gemini app into a true assistant’
Google is building its own OpenClaw alternative — Remy ‘elevates the Gemini app into a true assistant’News The OpenClaw-style agent, dubbed ‘Remy’, is reportedly being tested by developers internally
-
 Four things you need to know about OpenAI’s new workspace agents for ChatGPT – including how to build your own
Four things you need to know about OpenAI’s new workspace agents for ChatGPT – including how to build your ownNews New ‘workspace agents’ from OpenAI will automate tasks for workers and can be customized for specific roles
-
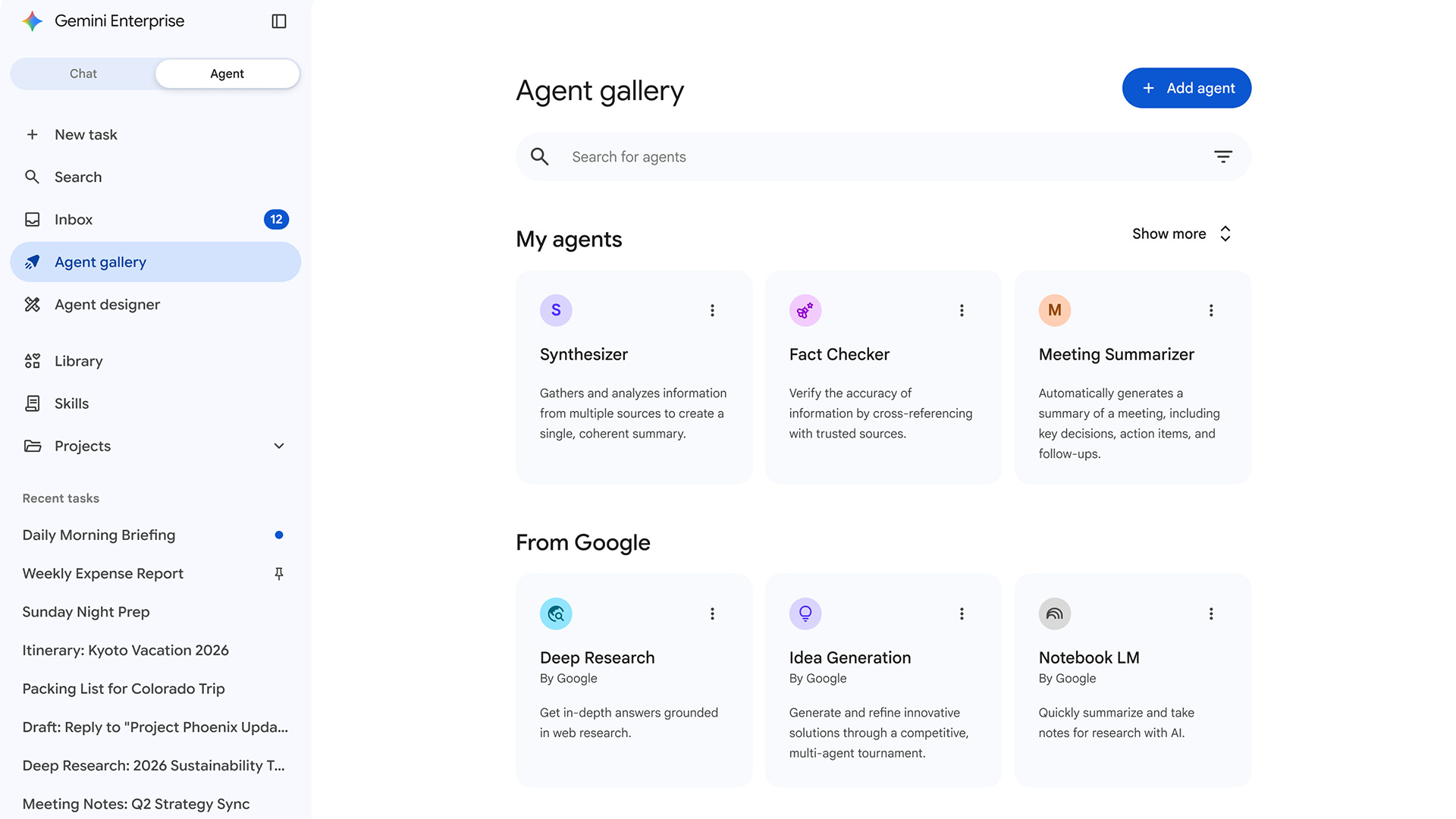 Google expands Gemini Enterprise, consolidates Vertex AI services to simplify agent deployment
Google expands Gemini Enterprise, consolidates Vertex AI services to simplify agent deploymentNews Gemini Enterprise Agent Platform aims to help organizations to build, scale, govern, and optimize AI agents
-
 OpenAI says AI tools are paying dividends for small businesses, but uptake is sluggish in several UK regions
OpenAI says AI tools are paying dividends for small businesses, but uptake is sluggish in several UK regionsNews While some small businesses are seeing big benefits, many don't use AI at all
-
 Microsoft has a new AI poster child in Anthropic – and it’s about time
Microsoft has a new AI poster child in Anthropic – and it’s about timeOpinion Microsoft is cosying up to Anthropic at a crucial time in the race to deliver on AI promises







